When faced with a choice of production rules, Unger's Method works by
evaluating all possible partitions of the input string that can
correspond to the symbols on the right-hand-side of each option.
As an example, we take the grammar
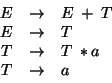
Suppose we are trying to match the string ``a![]() a+a''.
a+a''.
We may represent the initial situation as an attempt to match ![]() to this:
to this:
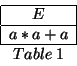
As there are two options for the right-hand-side, we enumerate these as:
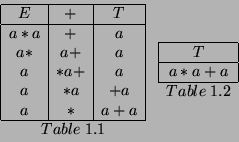
If we consider table 1.2 first, we can expand the production rules for ![]() to get two new tables:
to get two new tables:
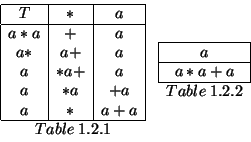
Now by just looking at the columns involving terminal symbols, we can tell that both of these are impossible. The only correct rows in table 1.2.1 should have a ``![]() '' in the second column and an ``a'' in the third: there are none. Similarly, in table 1.2.2 it is clearly impossible for ``a'' to be the same as ``a
'' in the second column and an ``a'' in the third: there are none. Similarly, in table 1.2.2 it is clearly impossible for ``a'' to be the same as ``a![]() a+a'', and so we reject this also.
a+a'', and so we reject this also.
Going back then to table 1.1, we can see that some of its rows can also be eliminated. The middle column has the terminal ``+'' in it, so the only acceptable rows are those with a ``+'' in this column: that is row 1. So the table now looks like:
Now for each row that is left, we must expand both ![]() and
and ![]() , and consider their possible partitions.
, and consider their possible partitions.
Since we know that ![]() can generate ``a'' (we could write out the tables to prove this), we can proceed with analysing
can generate ``a'' (we could write out the tables to prove this), we can proceed with analysing ![]() . Expanding out we get:
. Expanding out we get:
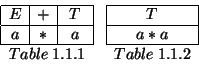
We can throw away table 1.1.1 immediately since ``+'' won't match with ``![]() ''. Expanding the remining table gives us
''. Expanding the remining table gives us
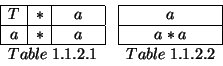
The second table can be thrown away, and expanding ![]() shows that table 1.1.2.1 does indeed represent a correct parse.
shows that table 1.1.2.1 does indeed represent a correct parse.