Parsing is the process where we take a particular sequence of words
and check to see if they correspond to the language defined by some
grammar.
Basically what we have to do is to show how we can get:
| from | the start symbol of the grammar |
| to | the sequence of words that supposedly belong to the language |
| by | using the production rules |
We can do this by constructing the appropriate parse tree for the sequence of words, which is simply a graphical way of listing the production rules that we have used.
Considering the following simple grammar for arithmetic expressions:
Here there are just two non-terminals, ![]() and
and ![]() (where
(where ![]() is the start symbol); the terminal
symbols are: +, -, *,
is the start symbol); the terminal
symbols are: +, -, *, ![]() , (, ), num.
, (, ), num.
Suppose the lexical analysis phase has given us the sequence of tokens which correspond to:
(num + num) ![]() num. We can parse this as follows:
num. We can parse this as follows:
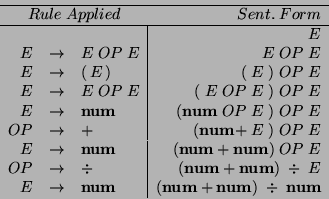
We say that ![]() derives (num + num)
derives (num + num) ![]() num, and write:
num, and write:
We can represent the above derivation graphically by means of a parse tree.
The root of the tree is the start symbol ![]() , and its leaves are the terminal
symbols in the sentence which has been derived. Each internal node is
labelled with a non-terminal, and the children are the symbols obtained
by applying one of the production rules.
, and its leaves are the terminal
symbols in the sentence which has been derived. Each internal node is
labelled with a non-terminal, and the children are the symbols obtained
by applying one of the production rules.
=1.00mm
![\begin{picture}(95.00,100.00)
\put(70.00,100.00){\makebox(0,0)[cc]{E}}
\put(70.0...
...55.00,37){\vector(0,-1){13.5}}
\put(40.00,37){\vector(0,-1){13.5}}
\end{picture}](img127.png)
There are two ways of constructing a parse tree whose root is the start symbol and whose leaves are the sentence:
Both of these methods will be discussed in detail later.