



Next: Non-Deterministic Finite-State Automata
Up: REGULAR LANGUAGES
Previous: REGULAR LANGUAGES
Contents
Regular expressions are used to define patterns of characters; they
are used in UNIX tools such as awk, grep, vi and, of course,
lex.
A regular expression is just a form of notation, used for describing
sets of words. For any given set of characters 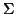 , a regular expression over is defined by:
, a regular expression over is defined by:
- The empty string,
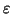 , which denotes a string of
length zero, and means ``take nothing from the input''. It is most
commonly used in conjunction with other regular expressions eg. to
denote optionality.
, which denotes a string of
length zero, and means ``take nothing from the input''. It is most
commonly used in conjunction with other regular expressions eg. to
denote optionality.
- Any character in may be used in a regular expression.
For instance, if we write a as a regular expression, this means
``take the letter a from the input''; ie. it denotes the
(singleton) set of words {``a''}
- The union operator, ``|'', which denotes the
union of two sets of words. Thus the regular expression a|b
denotes the set {``a'', ``b''}, and means ``take either the letter
a or the letter b from the input''
- Writing two regular expressions side-by-side is known as concatenation; thus the regular expression ab denotes the set
{``ab''} and means ``take the character a followed by the
character b from the input''.
- The Kleene closure of a regular expression, denoted by
``*'', indicates zero or more occurrences of that expression. Thus
a* is the (infinite) set {, ``a'', ``aa'',
``aaa'', ...} and means ``take zero or more as from the
input''.
Brackets may be used in a regular expression to enforce precedence or increase clarity.
Next: Non-Deterministic Finite-State Automata
Up: REGULAR LANGUAGES
Previous: REGULAR LANGUAGES
Contents
James Power
2002-11-29